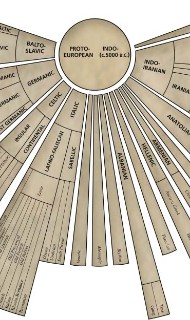
For generations, scholars have compared Sanskrit, Greek, and Latin and observed a lattice of systematic similarities. To account for these correspondencesand for parallel patterns across dozens of other tongueslinguistics posits a reconstructed ancestor, Proto‑Indo‑European (PIE). This language is not directly attested in inscriptions; rather, it is a scientific model built from converging evidence across the Indo‑European languages.
In modern classifications, Indo‑European comprises a large family that includes Indo‑Iranian (Sanskrit and its descendants, plus Iranian languages), Hellenic (Greek), Italic (Latin and the Romance languages), Celtic, Germanic, Balto‑Slavic, Anatolian, Tocharian, and others. Depending on criteria, scholars have counted hundreds of varieties; one widely cited enumeration listed approximately 439 languages and dialects as of 2009. While totals vary by method, the core insight remains: Sanskrit, Greek, and Latin are sisters that share an older common source rather than standing in an ancestor–descendant relationship to one another.
PIE is reconstructed primarily through the comparative method. Researchers identify regular sound correspondences among cognates, propose underlying proto‑sounds, and test whether those reconstructions predict broader patterns. Classic examples illuminate the method and often spark an early “aha” for learners: Sanskrit pitṛ, Greek patēr, and Latin pater (“father”); Sanskrit mātṛ, Greek mētēr, and Latin mater (“mother”); Sanskrit trayas, Greek treis, Latin trēs, and English three; Sanskrit nāma, Greek onoma, Latin nōmen, and English name. The sheer regularity of these correspondences, extending through grammar and morphology, anchors the PIE hypothesis.
Crucially, similarities are governed by sound lawssystematic, exception‑limited rules discovered in the 19th century. Grimm’s Law and Verner’s Law explain how Proto‑Indo‑European stops shifted in Germanic (e.g., PIE *p → f in English father, alongside Latin pater). Grassmann’s Law, independently observed in Sanskrit and Greek, accounts for the dissimilation of aspirated stops (e.g., Sanskrit dadhāti versus Greek tithēmi “to put”). The laryngeal theory, now widely accepted, reconstructs consonants (*h₁, *h₂, *h₃) that influenced adjacent vowels and left visible traces in Hittite (written with signs transliterated as ḫ), elegantly explaining long‑standing puzzles in Sanskrit and Greek vowel patterns.
Beyond sounds, morphosyntax powerfully links the family. PIE is reconstructed as a richly inflected language with multiple cases (commonly eight: nominative, accusative, genitive, dative, ablative, locative, instrumental, and vocative), three grammatical numbers (singular, dual, plural), and at least three genders (masculine, feminine, neuter). Verbal morphology encoded tense–aspect–mood distinctions and person–number agreement. Vedic Sanskrit preserves many archaic features of this system, which makes it exceptionally valuable for comparative reconstruction, while Greek and Latin provide independent confirmation and additional archaic retentions.
A hallmark of Indo‑European structure is ablautsystematic vowel alternations tied to grammar and word formation. Alternations like e‑grade, o‑grade, and zero‑grade underlie families of words: compare Latin ferō “I carry,” Greek pherō, and Sanskrit bharāmi, all reflecting the PIE root *bher‑ “to carry,” which also surfaces in English bear. Ablaut interacts with accent placement and the laryngeals, and it helps explain why cognate forms vary in predictable ways across Sanskrit, Greek, and Latin paradigms.
The reconstructed PIE sound system traditionally includes voiceless, voiced, and voiced aspirated stops (e.g., *p, *b, *bʰ), sibilants, resonants (r, l, m, n, y, w), and laryngeals. Alternative proposals, such as the glottalic theory, reanalyze aspects of the stop series to better account for typological asymmetries and the rarity of plain *b. While debate continues over fine details, the broad correspondences that unite Sanskrit, Greek, and Latin remain robust.
Attested early Indo‑European languages provide crucial anchors in time. Hittite and related Anatolian languages are recorded by the 2nd millennium BCE; Mycenaean Greek appears in Linear B tablets by the 14th–13th centuries BCE; and Vedic Sanskrit hymns, preserved in the Ṛgveda, reflect a highly archaic Indo‑Aryan stage. Tocharian, discovered in manuscripts from the Tarim Basin, reveals a distant eastern branch and reminds researchers that the Indo‑European story spans from Atlantic Europe to Central and South Asia.
Vocabulary reinforces the picture of a shared heritage and offers windows into past lifeways. The widespread reflexes of PIE *kʷékʷlos (“wheel”)Sanskrit cakra, Greek kyklos, Latin cyclus (via Greek), and English cyclesuggest technological knowledge common to early Indo‑Europeans. The celebrated PIE root for “horse,” *h₁éḱwos, surfaces as Sanskrit aśva, Latin equus, and (via a distinct development) Greek híppos. Kinship terms, pastoral words, and basic numerals pattern so consistently across Sanskrit, Greek, and Latin that chance resemblance is effectively ruled out.
PIE’s geographic homeland remains under active, evidence‑based debate. The Steppe or Kurgan hypothesis situates the homeland in the Pontic‑Caspian steppe, correlating dispersal with Bronze Age pastoralism and wheeled transport. The Anatolian hypothesis ties earlier spread to Neolithic farming expansions. South Asian perspectives, including Out of India scenarios, propose models in which Indo‑European lineages radiate from the Indian subcontinent. Each framework integrates linguistic, archaeological, and increasingly, ancient DNA data. Current scholarship emphasizes that language dispersal, material culture, and genetics do not map one‑to‑one; robust conclusions demand triangulation and humility.
Ancient DNA has deepened the conversation by tracing population movements and admixture events, including steppe‑related ancestry signals in parts of Eurasia and South Asia. These findings, while significant, are not determinative of language on their own. Languages can spread by élite dominance, trade networks, education, or spiritual prestige, often without large‑scale migration. For this reason, linguistics, archaeology, and genetics are best treated as complementary lines of evidence rather than as interchangeable proxies.
For the dharmic world, the Indo‑European perspective enriches appreciation of a shared linguistic heritage without diminishing the uniqueness of traditions. Sanskrit anchors Hindu śruti and smṛti literature; Pāli and Prakrits transmit foundational Buddhist and Jain canons; and Punjabi (written in Gurmukhi) expresses the living spirit of Sikh scripture. Recognizing historical kinship among these and related languages fosters unity in diversitya principle resonant with Vasudhaiva Kutumbakamwhile honoring each path’s philosophy, ethics, and aesthetics.
It is equally important to distinguish language from script. Indo‑Aryan languages have been written in Brahmi‑derived scripts such as Devanāgarī, Śāradā, and Gurmukhi, among others; Greek innovated its own alphabet from a West Semitic source; Latin adapted and evolved an Italic script. Shared linguistic ancestry does not imply shared writing systems, and shifts in script often reflect cultural exchange, pedagogy, or technological change rather than a change in the language’s lineage.
Common misconceptions can be set aside with careful evidence. PIE is not a political construct but a testable scientific reconstruction supported by predictive sound laws and morphological parallels. Nor does the PIE model claim that Sanskrit descends from Greek or Latin, or vice versa; instead, all three descend from an earlier common source. Likewise, scholarly consensus holds that reconstructed forms (marked with an asterisk, e.g., *pH₂tḗr) are hypotheses, not certaintiesuseful precisely because they are continually refined by new data.
Methodologically, comparative reconstruction is bolstered by internal reconstruction (inferring earlier states from irregularities within a single language), typological reasoning, and, cautiously, lexicostatistical and Bayesian phylogenetic approaches. Computational techniques can reveal broad patterns, but they work best when constrained by philological expertiseprecisely the kind of expertise that Sanskrit, Greek, and Latin studies have cultivated for centuries.
Not every similarity signals common descent. Areal diffusion, borrowing, universal tendencies, and chance resemblance all leave traces in the record. The comparative method succeeds because it seeks comprehensive, law‑governed correspondences across basic vocabulary, inflectional morphology, and core grammardomains that resist borrowingthereby separating deep inheritance from surface contact.
Seen in this light, Indo‑European linguistics offers practical benefits for readers of dharmic texts. Understanding Sanskrit roots, ablaut, and sandhi deepens engagement with the Vedas, Upaniṣads, and epics. Awareness of Indo‑Aryan–Iranian connections clarifies parallels with Avestan hymns. Sensitivity to historical phonology supports precise mantra recitation, while comparative grammar illuminates commentarial traditions that analyze forms with extraordinary subtlety.
Ultimately, Proto‑Indo‑European is best understood as a scholarly bridge: a model that links languages and peoples without flattening their identities. By embracing rigorous evidence and honoring the plurality of Hinduism, Buddhism, Jainism, and Sikhism, it becomes possible to celebrate a shared linguistic inheritance while safeguarding each tradition’s distinctive voice. The result is a deeper, more empathetic understanding of South Asia’sand Eurasia’slinguistic and cultural tapestry.
Inspired by this post on Dandavats.










